架构概览
内核态采样 → 三层过滤器 → 环形缓冲区 → 时序排序 → 分析器实时处理
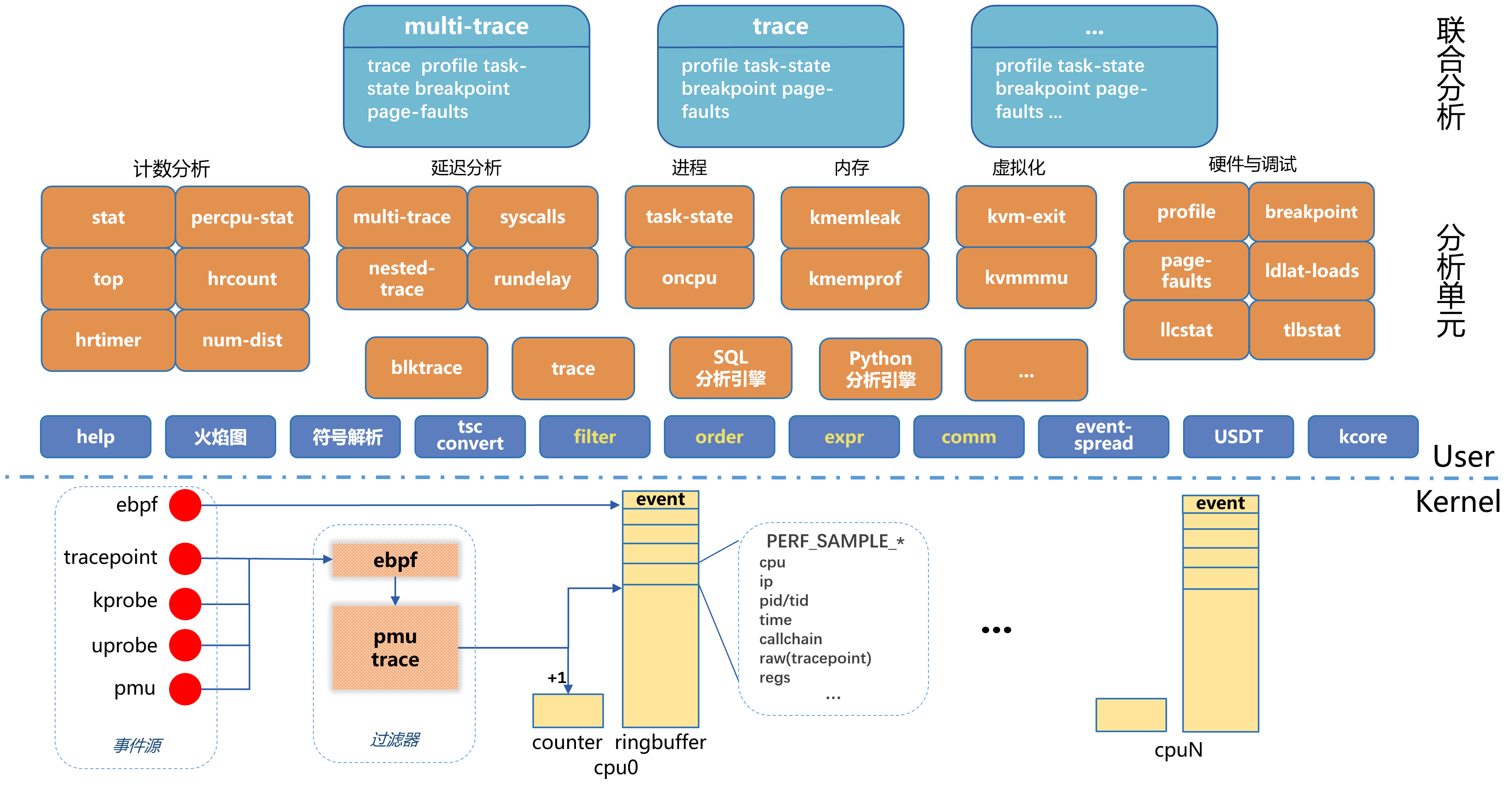
内核态采样 → 三层过滤器 → 环形缓冲区 → 时序排序 → 分析器实时处理
内核 maintainer 在关键流程上预埋了 tracepoint,理解这些点就是理解内核
内核 maintainer 在调度、内存、文件系统、IO、网络等子系统的关键节点预埋了 tracepoint,每个点标记一个关键的状态转换或决策点。
解决性能问题的本质,就是跟踪和分析 tracepoint 之间的关系 —— 事件的先后顺序、延迟、配对、聚合。
perf、ftrace 可以采集原始 tracepoint 事件,但一秒内就能产生数十万条。海量原始数据既超出 AI 上下文窗口,也远超人的阅读能力,靠逐条分析无法定位问题。
在用户态实时处理事件关系,将海量事件压缩为分析结论:
perf-prof 将数十万条原始事件压缩为数行结论,比 AI 直接消化原始事件流高效几个数量级。
事件在内存中实时处理后直接丢弃,可长期运行,安全可靠
采样事件不写文件,处理后直接丢弃。无磁盘瓶颈,适合长期运行。
支持 Linux 3.10+(仅需 perf_event),远低于 BCC/bpftrace 的 4.1+ 要求。
multi-trace 事件配对与延迟分析,还原中间事件细节。
eBPF / trace event / PMU 三层内核态过滤。支持 eBPF 过滤器和 BPF skeleton 分析器。
覆盖 CPU、内存、调度、IO、虚拟化等场景,紧急问题直接拼命令。
事件自动转为 PerfEvent 对象,只需了解字段即可分析,无需编写内核代码。
内建火焰图折叠栈和延迟热图,一条命令完成可视化。
通过 virtio-ports / TCP 传播事件,Guest ↔ Host 跨系统联合分析。
提供 perf-prof skill,AI 自动选择分析器、拼命令、解读结果。
在性能、灵活性、跟踪时效、兼容性之间权衡
类比编程语言:C/C++/Rust › JavaScript/TypeScript › Python › Shell
性能影响最小化,高频事件内核态聚合,新内核(4.1+)环境
旧内核(3.10+)且需要性能保障;延迟根因分析;紧急问题快速拼命令
无长期采样需求,短时采样后离线分析即可
降低跟踪分析的门槛,让更多人能分析性能问题
help 生成模板后修改每个分析器都是独立模块,针对特定场景优化
| 分析器 | 功能 | 领域 |
|---|---|---|
| profile | CPU 采样:热点函数定位、火焰图,支持内核/用户态 | CPU |
| trace | 通用事件跟踪:打印事件与调用栈,支持 kprobe / uprobe | 跟踪 |
| multi-trace | 多事件关系:延迟分析、事件配对、--detail 还原中间细节 | 延迟 |
| top | 键值聚合统计:按进程/线程/自定义键排序 | 统计 |
| sql | SQL 聚合查询:基于 SQLite 的灵活事件分析 | 统计 |
| task-state | 进程状态监控:R/S/D/T 耗时分布与根因分析 | 调度 |
| oncpu | CPU 运行监控:实时显示各 CPU 运行进程及时间 | CPU |
| blktrace | 块设备 IO:全生命周期延迟、毛刺检测 | IO |
| kvm-exit | KVM VM-Exit/Entry 延迟分析与退出原因统计 | 虚拟化 |
| kmemleak | 内存泄漏检测:内核/用户态分配追踪 | 内存 |
| python | Python 脚本:自定义脚本处理 perf 事件 | 脚本 |
| syscalls | 系统调用延迟:完整生命周期分析 | 延迟 |
| rundelay | 调度延迟:唤醒到实际运行的延迟 | 调度 |
| kmemprof | 内存分配统计:分配器热点与大小分布 | 内存 |
| bpf:kvm_exit | 基于 eBPF 的 KVM 退出事件生成 | 虚拟化 |
| watchdog | 硬锁/软锁检测:预测 lockup 并输出内核栈 | 调试 |
| irq-off | 中断关闭检测:定位长时间关中断代码段 | 调试 |
| num-dist | 数值分布:任意字段的直方图与百分位 | 统计 |
| hwstat / llcstat / tlbstat | 硬件计数器:IPC、LLC 命中率、TLB 命中率 | 硬件 |
| breakpoint | 硬件断点:监控指定地址的读写 | 调试 |
快速定位合适的分析器
采样热点函数,生成火焰图
profile oncpu cpu-util
唤醒 → 运行延迟、进程状态分析
multi-trace rundelay task-state
块设备 IO 全链路延迟、毛刺检测
blktrace
分配/释放配对追踪,泄漏字节统计
kmemleak kmemprof page-faults
VM-Exit 延迟与退出原因统计
kvm-exit bpf:kvm_exit kvmmmu
状态耗时分布与堆栈定位
task-state syscalls
系统调用延迟全链路分析
syscalls multi-trace
按维度聚合,Top-N 排序
top sql num-dist stat
安装构建与常见分析场景示例
# Install dependencies
yum install -y xz-devel elfutils-libelf-devel libunwind-devel python3-devel
# Clone and build
git clone https://github.com/OpenCloudOS/perf-prof.git
cd perf-prof && make# Sample kernel CPU hotspots
perf-prof profile -F 997 -g --exclude-user --than 30
# Generate flame graph
perf-prof profile -F 997 -g --flame-graph cpu.folded
flamegraph.pl cpu.folded.folded > cpu.svg# Scheduling latency > 4ms, with intermediate details
perf-prof multi-trace \
-e sched:sched_wakeup,sched:sched_wakeup_new \
-e 'sched:sched_switch//key=next_pid/' \
-k pid --order --than 4ms --detail# Track kmalloc/kfree pairs
perf-prof kmemleak \
--alloc "kmem:kmalloc//ptr=ptr/size=bytes_alloc/stack/" \
--free "kmem:kfree//ptr=ptr/" \
--order -m 128 -g# IO latency > 10ms
perf-prof blktrace -d /dev/sda -i 1000 --than 10ms
# IO latency heatmap
perf-prof blktrace -d /dev/sda --heatmap io_lat# D state > 100ms, with call stacks
perf-prof task-state -D --than 100ms -g
# S state analysis
perf-prof task-state -S -p <pid> --than 50ms -g